This document
about the PIMO Ontology is outdated and replaced by:
http://dev.nepomuk.semanticdesktop.org/wiki/PimoOntology
http://dev.nepomuk.semanticdesktop.org/repos/trunk/ontologies/pimo/latex/pimo.pdf
The ontology is used in gnowsis 0.9.* but not in NEPOMUK and should not be used
in current development.
Technical Report - DRAFT!
The Semantic Desktop needs a well-thought use of ontologies and ontology languages. Existing ontology languages like RDF/S, OWL, SKOS and Topic Maps are very well suited for certain application areas, but do not fulfill some of the requirements given on the Semantic Desktop. In this report, a new ontology language, extending RDF/S, is proposed, the PIMO ontology language, which addresses the requirements of the Semantic Desktop and uses existing solutions as an inspiration to build a suitable solution. The language contains a core upper ontology, defining basic classes for things, concepts, resources, persons, etc. and also stops at these basic entities. Extending the ontology definitions of classes and relations is possible by PIMO-domain ontologies. The core application area of the PIMO-language is to allow individual persons to express their own mental models in a structured way, the different mental models can then be integrated based on matching algorithms or on domain ontologies. Based on the core upper ontology elements, each user can extend his personal mental model in an open manner.
Accompanying to the description of the ontology is a RDF/S version of the ontology language, created using the popular Protégé tool. An example of the mental model of a user is given, the fictional user "Paul" is further described. With the gnowsis-beta open source software, an implementation based on the PIMO language exists, that allows validating ontology files. A web-service for that will be provided soon. The ontology language, this document, the open-source reference implementation and the example documents can provide a stable basis for discussions on this topic and allow you to extend your own work.
This report contains a description of the problems faced with personal ontologies, gathers requirements and shows a possible ontology language for personal ontologies. Example data and a user interface mockup give more practical hints. Common problems in the field are not ignored but addressed and possible solutions suggested. The target audience are ontology authors or application developers that are interested in creating ontologies for the purpose of personal information management, further researchers from the Semantic Desktop field will find a summary about the practical and theoretical background of our work. The gnowsis developers at DFKI are a good example of such a group.
As technical architecture we will reference the Semantic Web, so you should be familiar with the RDF(S), and OWL standards and know how to build ontologies using OWL or RDF(S). We will also reference some semantic and philosophical ideas from Topic Maps, to illustrate the problems and solutions from a different angle. The reader is expected to have a level of familiarity with RDF(S) that at least corresponds to the tutorial material in [RDF-PRIMER], [RDFS], [OWL]. Knowledge about Topic Maps would be very helpful to understand our ideas [TM-empolis]. For a background on the technical aspects of the Semantic Desktop, you may refer to [Sauermann2003]. We will also refer to philosophical findings, giving an introduction to these in this document.
Introduction
Language used in this document
Requirements in Personal Information Management (PIM)
Communication, Import, and Merge
Analysis of Existing Ontology Languages
The PIMO Solution
Areas in the land of PIMO
Representing Things
Identification in the PIMO
Metadata of a PIMO
Importing domain ontologies - what's with foaf?
Hiding things
Automatic Creation of Things from ResourceManifestations
Validation of a PIMO
User Interface Example
Summary
Acknowledgements
Frequently Asked Questions
References
Footnotes
Traditionally, Personal Information Management (PIM) is about managing calendars, contacts, and e-mails. If we make a reality check, every piece of information a person encounters has to be managed. Hence PIM in a digital world is about everything accessed by a person through his or her computer, not just calendars, contacts, and e-mails.
Googling for PIM, we find products like the KDE-PIM, solving similar problems like Microsoft Outlook, synchronisation tools like amphire or intellisync, and niché products like the text processor treepad. On wikipedia, the personal information manager roughly covers what can be categorised as "Microsoft Outlook lookalike". To manage information as such, ideas and thoughts, we find products that allow us to express our ideas using bubbles and arrows, mind-manager or mind-mapping tools. They might even be standardized like topic maps [XTM] or use the Resource Description Framework [RDF-PRIMER] like mindraider does. There are integrated research prototypes like haystack which also aim at PIM in a very elegant way.
In 2003, Leo Sauermann started the gnowsis project, which aims at building a so called "Semantic Desktop", a platform that extends the operating system to allow an enhanced PIM, based on Semantic Web technology.
Authoring and using ontologies for personal information management is not enough, in the gnowsis project we aimed at bringing the ontology into the daily applications of the end user. Here is a short description of the main ideas behind gnowsis.
The Semantic Web is a way of enriching the existing WWW with data.
This technology may also be used on a personal computer. Similar to the Web, a
server application publishes the available data. This local Semantic Web Server
can be used to access the information stored on the PC. Files and other
resources can be used like Web resources. They are identified by their URI and
links can be created from one document to another. The existing data is
available in the RDF syntax and can be used by any application. Interaction
between the applications is simplified by these standards.
By taking the Semantic Web technologies and using them on a personal computer, a
semantic layer in system architecture is created. Parallel to the existing
access to resources using already installed applications, they can be accessed
through the Semantic Web server. The resources are identified independent of
their file format. Based on this layer, a system-wide classification system can
be created. Concepts like private or business are represented once in the
system and can be reused in all applications. The class my XML Lecture is
represented similar to a group in a web directory (like yahoo), the class can
contain files, emails, webpages, etc. All resources can be identified by their
URI and can be opened using a browser like program. A crawler similar to google
can be built on top of such a system to create a full text index of all existing
text data.
The links between local resources are bidirectional, this is an extension of the
common WWW principle of unidirectional links. A relation between two resources
can be entered at one place into the system and can be found from all connected
resources.
As shown by these examples, bringing web technologies to a personal computer can
be used in many ways. Accessing the data on the computer through the interface
of a Semantic Web server creates a new perspective of existing data, they can be
addressed by URIs and organized in web directories etc.
(from [Sauermann2003], page 15, with new highlighting).
Existing applications are not replaced but instead enhanced with semantic features. Users can create an ontology and use it from within their normal e-mail client or text processor. Software plugins to these applications can connect to it and relate the current file to another photo using semantic web technology.
Using the standard RDF ontology languages, we came to a dead end when faced with complex problems in the field of PIM. The RDF standard and especially OWL and RDF(S) as ontology languages are not enough for personal information management. During the last years of implementation and testing, these flaws in existing approaches appeared:
The goal at hand is now to create a simple, minimal ontology language that fulfills our requirements for the Semantic Desktop and combines the best existing solutions while avoiding the usual pitfalls. Luckily, others have already invested much time into creating ontologies for different application areas, and we learned much from their efforts. These findings can now be used by us to transfer best practice into the field of PIM. We found these existing approaches very useful as input for this document and will discuss them:
These existing approaches can help us very much to find an ontology for PIM that meets our requirements. This report will start with listing the requirements we have found for ontologies in PIM, listing features, our experiences from the gnowsis project, our findings and solutions for identification of things. Then we will focus on the background from the information sciences and have a look at mapping and merging of ontologies. The requirements we have found are then mapped to the existing ontology languages we focus on (RDF-S, SKOS, XTM). Based on all these requirements we design our solution for a PIM ontology. The solution will consist of an ontology language, an upper ontology defining some basic classes and instances and one example of how one person can use our solution. We will also show how a user interface might look like to edit the ontology and propose ways how to integrate the ontology to applications using plugins.
Finally, we face ourselves with frequently asked questions that will typically come up in your mind after reading this report. We also try to answer these questions.
As we cross different ontology languages (RDF, SKOS and Topic Maps) and also reference to cognitive science, reading this document is not so simple if you do not think in the same language as this document was written in.
Common "Microsoft Outlook and its lookalikes" tools offer a way to write down data to be used for PIM.
For the data handling tasks like calendars, address book, process support, and e-mails we will not include a solution in our ontology. As these documents are already well handled by existing applications, we will only represent them on a very basic way. To be clear on this point: the suggested ontology of this report does not provide the perfect Microsoft Outlook data model, please use the software of your choice and their data model. Concentration is on the things that are badly handled by current PIM solutions: tagging and all the higher ontological features like inference and relations.
Beyond the normal look at PIM, which is address book, calendar, todo lists and e-mails, we want to help people use computers to organize their information life. People organize their files in a very personal way, and often they employ a categorization scheme for their file folders or bookmark folders. The way of classifying files has grown over years and cannot be reproduced by others - the same extent to which people are different, their filesystems are different. On MS-Windows filesystems (without soft links) each file remains in exactly one folder and folder hierarchies cannot loop. This classification system only allows the creation of taxonomies, where one file can be placed in one class. So typically, the folders have a partitive semantic: subfolders are part-of the super-folder and cannot be part-of any other folder.
But these schemes only apply to file systems, with the semantic features of RDF we can go beyond these basic features. Based on the previous work mentioned above and other existing ontologies [SKOS-Effort, XTM], we assume that people will need the following features on a Semantic Desktop:
If you are familiar with Topic Maps, you will find the basic concepts of them in above list, if you are yet not familiar with Topic Maps, we encourage you to read the Topic Maps Handbook by Holger Rath, which is a very well written and colorful introduction to XTM [TM-empolis].
For a detailed look about part-of and has-part relations, have a look at the OWL W3C draft about that [OWL-partof].
From the experience of creating gnowsis, and an analysis of our work, we infer these requirements to a PIM system:
bring existing resources, files, e-mails, appointments, web-sites etc. into the ontology
separate resources from concepts
bring the ontology into existing applications via plugins
publish the ontology via an PIMO API so that the plugins work
allow the use of concepts throughout all software, similar to tagging
tagging documents/things using keywords.
allow the user to annotate any concept using free text and also data properties
make the use as simple as a wiki and a blog combined
allow the linking of any concept to any other concept
populate the ontology automatically by analyzing the user's data
relate existing file folders and email folders to concepts
synchronize folder structures with ontology structures
import external ontologies by copying, connect the copied concepts to the originals.
try to be compatible with the beauty and buzz of the FOAF-community
Based on our previous workshops[1] on the topic, and the discussions there with gnowsis end users and developers, we found that several features in personal information management are currently only available on the web and now move to the desktop. Tagging items using keywords is one of those features. It was requested again and again in end-user interviews and looking at related desktop and web products. A similar feature that is also relevant is the integration with existing folder and file hierarchies. Existing file folder hierarchies can be used to populate the ontology, these folders say much about the way people organize their mental models. So some parts of a PIMO can be populated automatically by looking at existing file folders, and the file folders are then linked to the created part in the ontology. Similar, structures found in email folders or in flickr tags can be used to generate. If the user has a flickr account or a weblog, the categories and tags can be analysed and linked into the PIMO.
The personal file-system of the user is a key point on the Semantic Desktop. There is much semantic to be found in folder structures: "I put project related files in the project folder. Inside the project folder, there is a sub-folder for each project". Here we find first the class "Project" and then instances of this class. Another semantic relation may be that of time: "All files created in the year 2005 are in the 2005 folder. Inside this folder, I have sub-folders for each month. The folder January is then a part-of 2005". A partition based on topics is possible: "I have a folder Topics where I put documents by topic inside the folder. I have the topics NewProducts, CRM, Sales, Accounting, Paragliding". Each file in the folder CRM would then have the topic CRM (customer relationship management) .
These implicit semantic relations hidden in the file-system, only
known by the user can be expressed explicitly. Files inside a folder
called "Marketing" are automatically assigned the semantics of "files
having topic Marketing". At
DFKI KM Lab we also evaluated
different methods how to use this information for natural language processing
and text indexing, connecting text documents to ontologies opens many doors. The
creation of subclass or instance relationships can also be automated based on
folder structures. Assume the user has a folder /myFiles/Topics/
containing many subfolders and each subfolder represents exactly one topic,
instances of the class "Topic" can then be created automatically from
these folders.
So called Active Folders are a possible name for this. Users can write rules that say what is part of a folder and what not. We see these in popular like iTunes, where you can create smart playlists2. In the upcoming windows file system winfs, we find a similar feature. From the scientific view, smart or active folders have been discussed starting with semantic filesystems. [SemFs]. We will name these features Active Folders in the discussion.
To define and implement Active Folders, part of the PIMO has to include classes and properties. An API-focused part of the ontology will deal with these.
A very important need that has risen over the years is the separation between resources and mental concepts. Right from the beginning of the project, also in discussions with others, we had a strong feeling towards the separation of resources (be they files, e-mails, web-pages) and concepts in the mental model. Although files, web-sites, e-mails are very important, they are just artifacts that contain and reference our mental models. This can also be seen in the Topic Maps standard, where there are two manifestations of documents. Using the language of this standard, it is possible to say:
First the web site "http://www.dfki.de/"
is a Topic of interest I work on. I represent it using the topic LeoTopics#www.dfki.de.
I can identify it using the field subjectIdentity
and resourceRef, an addressable subject. Second, the topic of
the company DFKI can be modeled using a topic LeoTopics#DFKI. As the dfki website (as a document)
mentions the topic DFKI, I can connect it via an occurrence.
You can find a detailed description of this topic in the Q&A section here.
From practical experience we have noticed that many topics are created with mistakes. At some point, the user may notice that "Rome" is not only a Topic, but instead a city. Therefore, the class of a thing has to be changeable. Also, the user may accidentally create two concepts that mean the same. For example for "Rome" and "Roma". Then, it has to be possible to merge different things, and to delete them. A need in all of these is checking the user's actions for validity. If "Rome" has a property that only a "City" can have, then the type cannot be changed or the property is removed during the process. This checking should be rule-based, obviously.
active folders and automatic creation of things
changing the type of a thing
multiple types for one thing (although - maybe not)
merging two synonymous things (merging two things that mean the same)
deleting things
rule-based checking of consistency
rule-based checking of change actions before they are executed
When people start to use Semantic Web technology to model ontologies, at a certain point they all hit a barrier, appearing concealed in question like:
Which URI do I give to the concept "Love"?
The true ontologist wants an answer that fits "the world", meaning that many other people will also agree to use the same URI to identify Love. That is the spirita of shared understanding and that's also where the problems start. The question is: what URIs are good to identify things, documents, concepts, persons, places, etc. On top of that, are these URIs useful in a distributed scenario or are they only useful on a single computer. Do they resemble a public agreement, are they standardized?
A PIMO system has to cope with something known as the "web's identity crisis" or "uri crisis". The problem is, that we use URIs to identify all of the above, we have URIs for documents, URIs for topics, URIs for everything. But what does a URI identify? Tim Berners-Lee wrote an interesting article to clear this problem, here is an exercise [TimblUri2002]:
1) What does "http://www.amazon.com/exec/obidos/ASIN/0679600108/qid=1027958807/sr=2-3/ref=sr_2_3/103-4363499-9407855" identify?
- A whale
- "Moby Dick or the Whale" by Herman Melville
- A web page on Amazon offering a book for sale
- A URI string
- All the above
When was the thing it identifed last changed?
Have you read the thing it identifies?
So basically, it is not so easy. Even if you think that you found a URI that identifies something, it may identify too much. That's why the article didn't solve the problem and people discussed in mailinglists forever, creating the impression that we are all stuck in an infinite loop of arguments. People stated that their URI scheme is better than yours. So Tim Berners-Lee wrote another article in 2005 about the same problem [TimblUri2005]. The proposed solution from the technical architecture group (TAG) is basically this (abbreviated):
The W3C Technical Architecture group eventually decided to resolve the architectural problem that if an HTTP response code of 200 (a successful retreival) was given, that indicated that the URI indeed was for an information resource, but with no such response, or with a different code, no such assumption could be made. This compromise resolved the issue, leaving a consistent architecture.
This may serve well from the technical side, but the semantic problem remains:
Where do we get URIs that identify topics/things/concepts?
Where is the URI for LOVE?
Shouldn't we place an HTML website at this URI so that people can click on it? (which the TAG solution seems to discourage).
Over time, others have also shone more light on it and proposed different solutions for this problem. David Booth wrote a very constructive article which can be found here [Booth2003]. He looks at the problem and then comes to the conclusion that there are many options and it cannot be determined which is "perfect". Most important is that we all use the same standard and things are compatible.
Steve Pepper has written an article on how to cure the web's identity crisis [Pepper2004]. The argumentation there is sounds correct. He proposes to solve the distinction of Resource VS Concept by using Topic Map syntax. Topic Maps do determine between addressable subjects and non-addressable subjects. The use of resourceRef or subjectIndicatorRef state a clear message about the topic in question: it is addressable (its a document) or it is not addressable (it is a concept) and in the Topic Map Community, usually one URI is not used in both uses. Also, the Topic Map community treats all concepts in the context of a Topic Map - every resource (be it addressable or not) is first re-instantiated in a local Topic Map using a local identifier (usually something like <topic id="opera">).
Pepper suggests to expand the use of rdf:about with rdf:subject and rdf:indicator to extend the identification. But Pepper didn't take the last needed step: to create a new view on RDF where each Resource is re-instantiated in the current ontology. He does not propose to create topics versus resources. We more tend towards SKOS: there, each Topic is called a Concept and is identified uniquely inside the SKOS ConceptScheme, using the URI of the concept scheme [SKOS-Effort].
Summing the identification problem up:
All these issues of identification can be considered harmful to any approach taken, and our solution should build on the existing work of our colleagues, not to make the same mistakes again. Our proposed solution is closely bound to the approach taken in Topic-Maps and can be found below.
Seen through the lens of a constructivistic worldview, we assume that people abstract from things percepted in the real world to a level of internal representation. A real world object is perceived as sensory impression and then triggers an internal representation, which might resolve to a mental concept. For example, the perception of the color red in the real world leads to a signal in the eyes which every human eye decodes the same. But each person may associate it a different mental concept, which may be the same or not. At this point, perception determines how the signal is matched against previous signals and other mental concepts. At least communication of the mental concept can happen via language - then the perception of the red lightwave is written or said as being "a red light", "rouge" or "ein rotes Licht".
So we differ, from the philosophical view between the following manifestations:
real world things (red light waves, a car, the chair I sit on right now)
perception of real world things
abstract topics (time, "love", organisations) that people can perceive and express
mental representation of things and topics
language we use to express our mental representation
documents containing this message
to come: semantic documents that contain the message better!
This model of information representation is relevant for the Semantic Desktop for two reasons
each manifestation from above should be considered in the ontology
when two people communicate, a concept switches manifestations and hopefully less information is lost when we do this right
In communication, facts about real world things or topics are expressed using a language. In the classical model by Shannon, the sender has an idea in his mind and expresses it using language, this results in a message. The message is sent to the receiver who reads the message, triggering again mental representations of the concept.

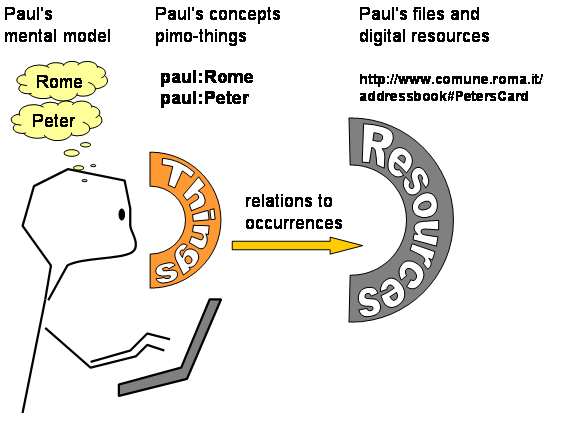
In semantic web communication, the communication process is different. The message is much more precise than normal verbal or textual communication. Single words from the text can be annotated using the relating concepts from the sender's ontology. The annotation of certain words (or the whole message) can be sent together with the message to the receiver. As an example, Paul sends an email to Peter that mentions Paul's concept of Rome in the text. In the packaged metadata sent within the email, Paul's concept of Rome is described using Paul's way of thinking. paul:Rome is linked to a public identifier from a website like wikipedia or wordnet.
Thus public thesauri like wikipedia or wordnet can play a role in this scenario as representing the "Plationian Representation", namely a public identifier that can be used to identify the concepts Bob and Alice talk about. We assume that the cultural background of Bob and Alice is overlapping enough that both recognize Wikipedia and can relate to the concepts described there. But this requires that both users have some personal ontology at hand. We hope that this way of communication is superior to normal e-mails today.
From the examples raised in the philosophical requirements, we see the need of communication and merging of different PIMOs.
If I want to represent IMDB movies in my ontology, I would have to include a movie ontology and the IMDB website somehow. The external movie ontology defines its own public identifieres, etc. When representing the movies in my PIM, they should be linked to the IMDB website to allow identification. When merging others and communicating, how to do this?
From the technical side, our goal is to find a solution that is scaleable and finds wide adaption in PIM applications.
a simple Ontology Language (minimal number of classes and properties)
easy to understand by developers
easy to understand by end users
compatible with best practice in current Semantic Web projects.
documented
examples of data models
The existing ontology languages can be compared to some of the requirements that were listed above.
|
Ontology Languages for PIM |
|||
| Features | RDF-Schema | SKOS | Topic Maps |
| PIM | |||
| abstract things | = may use RDFS-Class | X concept | X topic |
| addressable things | X resources | X concept | X occurrence, topic |
| documents | X resources | = may use rdf:Resources | X occurrence |
| naming different names for one thing |
= may use different languages | X different labels | X language, scope, variant names |
| naming same name for different things |
X | X | X |
| class-subclass relation | X | - no inheritance | X |
| class-instance relation | X | X narrowerInstantive 1 | X |
| part-of relation | - (suggested for owl) | X narrowerPartitive 1 | - |
| related information | - | X skos:related | X association |
| data properties | X rdfs:Property | - | = occurrences with resourceData, but not typed |
| document has topic | - | X skos:subject | X occurrence |
| time | - | - | - |
| Identification | |||
| identification of documents | X uri | = uses URIs of rdf:Resources | X resourceRef and xlink |
| identification of topics/things/concepts | X uri | X uri | X uri |
| approach to identify things across ontologies | - | = mapping ontology allows mapping, skos:primarySubject may point identity | X addressable subjects with resourceRef, non-addressable subjects with subjectIndicatorRef |
| Communication | |||
| Importing other RDF(S) ontologies | X via OWL:import or implicit by namespace | - | = (Topic Maps can be imported via mergeMap directive) |
| publish ontologies | X | X | X |
| merge ontologies | - no explicit rules how to merge semantically | X via mapping ontology | X via mergeMap directive |
Symbols:
1 ... in the SKOS Extensions Vocabulary [SKOS-ext]
Most of the other requirements from above are not part of the table and not handled by existing ontologies.
In this section we will describe the PIMO ontology.
The namespace of the PIMO-language is
http://ontologies.opendfki.de/repos/ontologies/pim/pimo#. We will
abbreviate this namespace with
pimo.
xmlns:pimo="http://ontologies.opendfki.de/repos/ontologies/pim/pimo#"
As ontology language RDF(S) is used. We also employ some extensions by the Protégé ontology editor for InverseProperties and cardinality restrictions.
The ontology itself and the according example can be downloaded here: [PIMO-lang, PIMO-example]
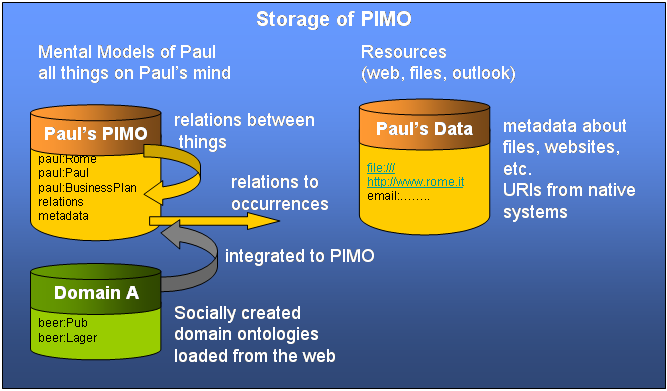
If the PIMO of a person is like a landscape, we can find different counties and regions in this mental land. When the user starts to explore the land of his own knowledge, the first area he reaches is Thing. There, the mental models are represented on an conceptual level, it is the land of knowledge, where a user models concepts that the computer can reflect, expressing ideas as near to the mental models as possible. Going further he comes to ResourceManifestation where the files and web/pages start. They are connected to the Things. Then there will be the mysterious caves of metadata about the ontology, where only programmers have to find their righteous path - InformationSystemConcept.
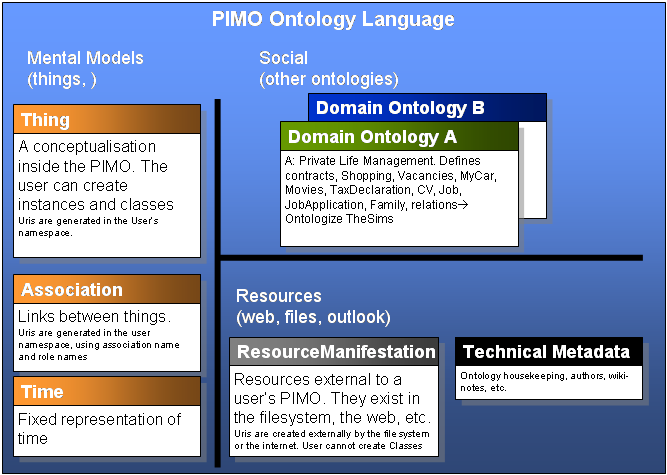
These three separated areas fulfill our requirement to separate resources from concepts. Abstract concepts are represented as Things, documents as resources.
 The subclasses of the
pimo:Thing and instances pimo:Thing are used to represent concepts that
come from the user's mental model. To the right you see the basic class
structure provided by the ontology. We find classes for a person, a group, a
location, document types, organization, event, task, project and topic.
The subclasses of the
pimo:Thing and instances pimo:Thing are used to represent concepts that
come from the user's mental model. To the right you see the basic class
structure provided by the ontology. We find classes for a person, a group, a
location, document types, organization, event, task, project and topic.
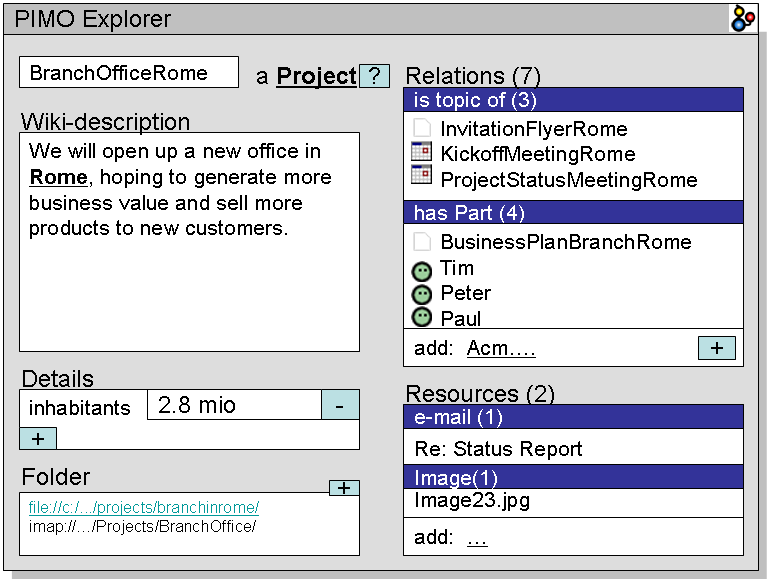
If we have a person called Paul, we can create Paul as instance of Person. If Paul wants to represent his friends Peter and Tim he can also create them as being a Person. When they are working in the city Rome, then they can create the thing Rome as being a city. When they plan to start a new branch office of their company in Rome, Paul can create the project BranchOfficeRome as being a project. If Paul has a meeting with others about the status of the project, he can create the ProjectStatusMeetingRome. You may have noticed that the labels given to these three things are words without funny characters nor spaces. For labeling things, we suggest to use wiki-names3. You might label things any way you want (from the technical point of view) but for these examples and practical reasons, wiki-names are much better. In our example, instances of the class pimo:Thing are:
Paul, Peter, Tim: instance of pimo:Person.
Rome: instance of pimo:City
BranchOfficeRome: instance of pimo:Project
ProjectStatusMeetingRome: instance of pimo:Meeting
By the way: you can download the example here: [PIMO-example].
Technically, the pimo:Things are RDF instances and therefore need
URIs to be identified. All things created by a user are identified using URIs
that come from a namespace personal to the user. That reflects the subjective
view of the world: the Thing Paul identifies as Rome is different from the Rome
of others, therefore the own URI. For Paul's namespace we use
gnowsis://paul@example.com/resources/pimo/. The namespace is abbreviated
using the name of the user, in our case
paul. More about it at the section about the
namespace. The names of things are therefore:
paul:Paul (Paul's concept of himself)
paul:Peter, paul:Tim, paul:Rome, paul:BranchOfficeRome, paul:ProjectStatusMeetingRome
If Paul faces a thing that is not of any type defined in the PIMO-language, he has to create a new class. Classes created by Paul have to be subclasses of Thing directly or of existing subclasses of Thing. For example, if Paul has the new concept of making business plans, he creates a new class paul:BusinessPlan. As these are a kind of document, paul:BusinessPlan is a subclass of pimo:Document. Technically seen, Paul says:
paul:BusinessPlan rdfs:subclassOf pimo:Document
paul:BusinessPlanRomeBranch rdf:type paul:BusinessPlan
Again, the classes are identified using URIs that come from Paul's personal namespace.
Things, classes and also properties can be labeled. The primary way of naming things is the pimo:label. The use of pimo:label is not restricted, you may use any string. There is exactly one pimo:label for a Thing, it is mandatory. If a thing has more names, the pimo:altLabel property can be used. These alternative names are useful during text search.
For various applications, a wiki-name of things may be useful. Wiki-names have to be unique and should not contain any symbols besides alphabetical letters and numbers, whitespace and funny characters should be avoided. Using CamelCase to combine more words into a wiki-word is suggested. Wiki-names help in tagging applications and other simple applications we envision for the semantic web. Also, the wiki-name might be a good candidate as local name in a URI.
To show a thing in a GUI, you can also provide icons to optically represent a thing or all instances of a class. You can assign icons to things, classes and properties. Use the pimo:hasIcon property to connect to icons, the icons have to be identified by a URL pointing to a local file or a web image.
Things can be, once defined, described in more detail using RDF properties. The most important property is that of the label, which names the thing and allows us to show it in a user interface. Labels are modeled using the RDFS:label property. The label may be any string value, but should be short and descriptive. For practical reasons, we also created a property pimo:label that allows us to label things inside the Protégé editor. Every thing must have a label. In the wiki context - when things are used inside text - wiki-names are needed.
Things can also be described in more detail using wiki-text. For this, use instances of the pimo:PimoWikiContent and connect them to things using pimo:hasWikiContent. Although using plain text would be fairly enough to describe things, wiki-text allows many researchers to create wonderful applications on top of the PIMO that will surely surprise us all.
Other describing properties can be added by creating sub-properties of pimo:DescribingProperty. Typically, the user will add properties to add comments, more descriptions, etc.
For example, if the user wants to enter the fact that Rome has 2.8 mio inhabitants, he may say:
paul:Rome - inhabitants - "2.8 mio".
This will automatically:
create a new rdfs:Property, a sub-property of pimo:describingProperty. The property is identified using the URI paul:inhabitants and has an rdfs:label "inhabitants".
create the triple: paul:Rome paul:inhabitants "2.8 mio".
We do not go into details about data-types here, everything is represented as a string at the moment. The main idea is:
The user creates describing properties on the go. If a new property is needed, it is instantly created. There is no strong domain/range typing, if the user wants to use the property in an "unintended" way, the user is always right to do so.
Practically, this means that we make "ontology by example". If the property paul:inhabitants is used primarily on cities, then when editing a city, the user interface should suggest to enter the paul:inhabitants and also list the existing values that Paul has entered ("2.8 mio").
The things inside the PIMO can have relations to each other, semantic links. In RDF these are called triples, in Topic Maps they are Associations. We decided to support both, but focus on the triples first. A few basic relations between things are assumed:
partOf - one thing is part of another.
hasTopic - a thing is about another
related - a thing is related to another
For each property, we also define an inverse property that tells us how the relation is from the other perspective. Here are the inverse properties and their names.
pimo:partOf - pimo:hasPart
pimo:hasTopic - pimo:isTopicOf
pimo:related - pimo:related
Notice that pimo:related is the inverse of itself. This means it is a symmetric property. If A is related to B, B is related to A. Looking at Paul's PIMO and his project, we find that:
paul:BranchOfficeRome - pimo:hasPart - paul:BusinessPlanRomeBranch
paul:BranchOfficeRome - pimo:isTopicOf - paul:ProjectStatusMeetingRome
paul:BranchOfficeRome - pimo:related - paul:Rome
The inverse look is this:
paul:BusinessPlanRomeBranch - pimo:partOf - paul:BranchOfficeRome
paul:ProjectStatusMeetingRome - pimo:hasTopic - paul:BranchOfficeRome
paul:Rome - pimo:related - paul:BranchOfficeRome
The meaning is, that the project is related to the city of Rome, that the business plan is part of the project and that the topic discussed at the meeting is Rome. If the user wants, he just might add all this as plain relations using pimo:related, this depends on the intentions of the user.
If the user wants to connect people to projects using a more precise semantic, he can create new properties. Any property created by the user must be a sub-property of either partOf, hasTopic or related. For example, the property "supervises" can be created to say that a person supervises something. The property will be inside the namespace of the user and has to have a super-property.
paul:supervises - rdf:type - rdf:Property
paul:supervises - rdfs:subPropertyOf - pimo:related
paul:supervises - rdfs:label - "supervises"
We also instantly create the inverse property, after asking the user what it may be called. "is supervised by" is a good name.
paul:supervises - protege:inverseProperty - paul:isSupervisedBy
paul:isSupervisedBy - rdf:type - rdf:Property
paul:isSupervisedBy - rdfs:subPropertyOf - pimo:related
paul:isSupervisedBy - rdfs:label - "is supervised by"
Note that sub-properties of related do not have to be symmetric.
As a rule, every property defined to connect one thing to another has to have an inverse property attached to it. This was a requirement made by Jean Rhomer that is realized here [Rhomer2005]. The inverse properties are needed to allow the user to make connections from any thing to any other thing. As all properties are directed (with the exception of pimo:related), the inverse properties are needed to express this.
If the user creates his own custom properties, each property has to have an inverse property connected to it automatically. If the user creates a property called "supervises" the inverse property must be created. It can be initialized with a bogus label like "inverse of supervises" which then can be changed by the user to "is supervised by".
Symmetric properties have themselves as inverse.
The user can create relating properties on the go. If a new property is needed, it can be created instantly. There is no strong domain/range typing, if the user wants to use the property in an "unintended" way, the user is always right to do so.
Practically, this means that we make "ontology by example". If the property paul:supervises is used primarily on people, then when editing a person, the user interface should suggest to enter the paul:supervises relation and also list the existing values that Paul has entered. The domains and ranges of properties may be defined to something specific, but as an alternative every property may be used on a pimo:Thing. The user interface may support a stronger typing and may support the user by suggesting useful properties that fit a certain type.
If binary relations are not enough, then an instance of the pimo:Association class is needed. For example, the role of Peter in relation to the branch-office project may be more complicated than just "manages the project". Peter may have begun his job sometime during the project and his job ended sometimes during the project, to be replaced by Jacob. Then the role Peter has had was only true for a certain amount of time. For this, the pimo:Role class helps, which is a sub-class of pimo:Association. By making an instance of pimo:Role, you can connect a person to a project and tell more about the role the person is having and also more metadata. For example, if another person is monitoring if Peter is playing his role good, you may add another person to the relation.
We will not go into further detail on associations, because we will not support them in the gnowsis beta GUI. If you need more information, please consult the XTM standard documents, where the concept of associations is explained in more detail. [XTM, TM-empolis, TAO].
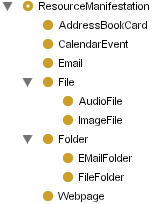 Files
on the hard-disk, web-pages or any other resource from local information systems
can be integrated to the PIMO of a user. The ontology does not end at the border
of our PIM application, it can be used to connect outside resources. The main
class to represent resources is ResourceManifestation. The class itself
and its subclasses are considered to be addressable resources in the sense of
RDF. We deliberately did not use the term Resource here, as our
pimo:Thing is also a resource in the meaning of RDF. On the right you see
typical classes of resource manifestations. Note that this scheme can be
extended by programmers, if you write an application that brings in a new
resource-type, create a new class for it. Comprehensive and useful class
structures for these ResourceManifestations are currently developed in the
Aperture project, where also adapters and extractors are written that can gather
such resources from a system and from the web [Aperture].
The resource structure is deliberately held very simple to be open to such
extensions.
Files
on the hard-disk, web-pages or any other resource from local information systems
can be integrated to the PIMO of a user. The ontology does not end at the border
of our PIM application, it can be used to connect outside resources. The main
class to represent resources is ResourceManifestation. The class itself
and its subclasses are considered to be addressable resources in the sense of
RDF. We deliberately did not use the term Resource here, as our
pimo:Thing is also a resource in the meaning of RDF. On the right you see
typical classes of resource manifestations. Note that this scheme can be
extended by programmers, if you write an application that brings in a new
resource-type, create a new class for it. Comprehensive and useful class
structures for these ResourceManifestations are currently developed in the
Aperture project, where also adapters and extractors are written that can gather
such resources from a system and from the web [Aperture].
The resource structure is deliberately held very simple to be open to such
extensions.
Instances of resources are not created by the user manually, they should always be created automatically by the system itself. They are identified using a URI that fits best - for a file, the file:// uri scheme, for an e-mail the messageid or IMAP uri. You only must guarantee that you can find the resource based on its URI and that the URI is unique on the desktop. You may also assure, that the URI is unique globally (in the whole world). The uri may be added to the resource as additional property pimo:uri but as the URI used as RDF identifier anyway, this is just to simplify modeling in Protégé
Example of such resources are:
branchinrome - The folder for the project files
file:///C:/Documents/Paul/documents/projects/branchinrome/
Picture23.jpg - A photo of the new office in Rome
file:///C:/myDocuments/Paul/documents/projects/branchinrome/photos/image23.jpg
Meeting at 29.9.2005 - meeting in outlook, topic is the
branch office in Rome.
gnowsis://paul@example.com/resources/outlook/appointment/00000000ECD4B99358B9814B9DAFE2255CD8AE9A44EF3000
Note that the third resource again has a funny looking URI, this time created using an identifier from Microsoft Outlook in combination with a Semantic Desktop URI scheme for a personal namespace (see below).
The main relation between mental concepts, expressed as pimo:Thing and files, expressed as pimo:ResourceManifestation are links of the type pimo:occurrence. An occurrence connection means that the mental concept expressed in the Thing X can be found in the document found in the ResourceManifestation Y. The definition of occurrences and the idea behind are taken from the XML Topic Maps standard, where an occurrence means [XTM].
An occurrence is any information that is specified as being relevant to a given subject.
Adding an occurrence triple between a thing and a ResourceManifestation expresses exactly that. The inverse property of pimo:occurrence is pimo:isOccurrenceOf.
These triples are generated by the user quite frequently and can be also created by the system automatically. For example, Paul notes that the website of the city of Rome is an occurrence of his thing paul:Rome by saying:
paul:Rome - pimo:occurrence - <http://www.comune.roma.it/>
<http://www.comune.roma.it/> - rdf:type - pimo:Webpage
There is a special occurrences in the PIMO, that is also used to identify a Thing: the pimo:occurrenceRef. It connects a thing to a public resource that can be used to identify the thing. More on this way of identification in the section about identification.
It is possible and allowed to create sub-properties of the occurrence property to express a certain kind of occurrence. We strongly discourage this because:
keep it simple. Represent the complex in the land of pimo:Thing
the occurrence is annotated anyway: the resourse has a type and some other properties
The principle of tagging is that resources are annotated using keywords. This has led to so called Folksonomies, where people tag web-pages or photos collaboratively. Using the PIMO, a simple kind of tagging is also possible: things are treated as tags and can be used to annotate resources using the occurrence relation. Any thing can be used to tag any resource, allowing the freedom of folksonomies on the desktop. This is a mixture of ideas from topic maps, folksonomies and RDF.
Here an example of how a user interface might look like that supports this kind of tagging of e-mails. The user enters a few letters of the intended tag, and the system searches for possible things to tag with. The user interface should filter to only show the most relevant tags, ie down to seven tags to show. In the gnowsis semantic desktop this will be supported by text analysis components.
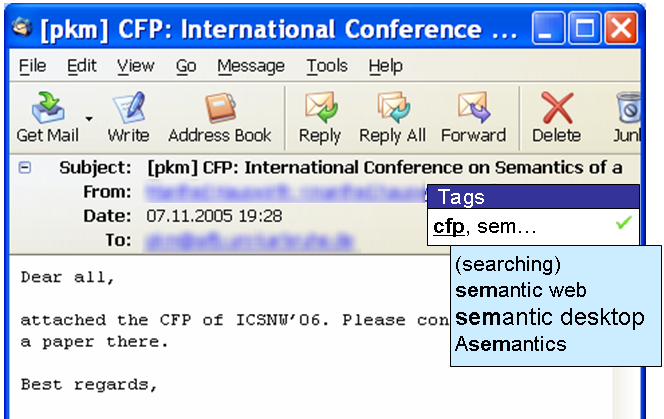
An e-mail is by definition a pimo:ResourceManifestation which can only be annotated using the relations pimo:occurrence and pimo:occurrenceRef. So when you want to just "tag" the e-mail, use these two relations. What happens now if you want to say that this e-mail is "related" to another thing or "part-of" this project? Or use more custom properties you created?
Then you reify the e-mail into an instance of type pimo:Thing (or a suitable subclass). So the first thing to do is ask the user what kind of document this e-mail is. Is it just a pimo:Document or is it a paul:BusinessPlan? Is it a paul:Invitation? Normally, you would reify text resources as Documents and for example address book entries as persons. After having it reified, the e-mail is now existing both as a ResourceManifestation and as Thing. The thing representing the e-mail can be annotated as you like, using your own properties etc.
During the process of reificating resources as things, it is surely possible to create as much data attached to the thing as possible. For example, you may relate other persons to the reified e-mail if they are mentioned in the to: and from: fields of the e-mail and if they already are existing as persons, or you might suggest to the user that the software can also reify the persons. More about this below, in section Automatic Creation of Things from ResourceManifestations. Result is:
email:123123 rdf:type pimo:Email (this existed)
email:123123 rdfs:label "Hi Paul!".
paul:MailHiPaul pimo:groundingOccurrence email:123123
Every person has - as already explained in philosophical background - a personal view of the world. So the mental models inside one's mind are subjective, personal. No two people conceptualize the concept "Rome" the same. This is reflected in the PIMO by employing a personal namespace for each user. The personal namespace could be any namespace that can be referenced and resources in the namespace can be downloaded via a protocol.
Sadly, the HTTP protocol is not a good candidate for the personal
namespace. Why? Because if Paul would use the namespace
http://www.example.com/~paul/pimo# to represent his mental models, this
would require that he is always online while modeling. Or, if he models offline,
it would require him to have a website called
www.example.com which he has to buy and host. Then he would have to install
a web-service there that serves his ontology. In the real world, most people do
not have a website, and those who have do not keep it up to date. Also, if Paul
has a change in his life that separates him from
www.example.com, his data would be lost (at
least frozen in the last state).
For the semantic desktop, and our gnowsis implementation (at least the March2006 version), we decided to use the gnowsis URI scheme to identify concepts and resources of individuals. The reason is that we do not use http as a communication protocol but instead use the peer-to-peer protocol XMPP (jabber). This allows any user to host the RDF resources where ever they want. If they are online, via the jabber protocol, if they are offline via the jabber server. For this and other reasons Frank Osterfeld and Malte Kiesel created the advanced jabber server nabu [ref-nabu]. Even if the user's do not employ the possibility of P2P communication, the idea of the namespaces are practical.
The URI scheme functions as follows:
gnowsis://[jabber id]/resources/pimo/
example: gnowsis://paul@example.com/resources/pimo/
The different parts are:
gnowsis - a semantic desktop implementation
jabber id - the jabber-id of the user (typically username@jabberhost)
resources - the place for rdf resources
pimo - the pimo of the user
This URI scheme is still subject to change and undocumented, but we think that the approach is right and will provide further discussion - later.
Things and classes of things inside the user's PIMO are identified using URIs from the user's PIMO namespace. These are clearly identifiers for the concepts behind. Refering to the article by Booth, we can say that RDF URIs used to identify instances of pimo:Class, pimo:Thing, and pimo:Slot identify the concept represented by these [Booth2003]. As the URIs in the personal information management domain identify the concept bound to the subjective view of the user, the namespace is bound to the person. We suggested to use Jabber-ids as part of the namespace, they are a technical identification of the user, like an e-mail address. See the section above.
Public identification for communicating things via the internet can be achieved using the pimo:occurrenceRef property. This points to a URI of a resource that can be used to publicly identify the thing. For the personal Thing "Rome (a City, a Location)" from Paul's PIMO, the website of Rome and the wikipedia entry can identify the city:
@prefix paul: <gnowsis:paul@example.com/resources/pimo/>. @prefix pimo: <http://ontologies.opendfki.de/repos/ontologies/pim/pimo#>. @prefix wikipediaen: <http://en.wikipedia.org/wiki/>. paul:Rome a pimo:City; pimo:occurrenceRef wikipediaen:Rome, <http://www.comune.roma.it/>.
If the identifier of a thing is not an addressable URI (=locator) but only an identifier, we recommend to use the property pimo:identifierRef or sub-properties of it. Books can be identified using their ISBN number in this field. They can also be identified using an occurrenceRef to the webpage of the book at the amazon.com website, to allow this common practice of identification.
To identify persons, either the property containing the pimo:jabberId can be used or a pimo:mbox to the e-mail-address of a person. URIs for e-mail addresses are inspired by the foaf-project. Which raises the problem of spammers and the use of e-mail addresses, they suggest to use the sha1-sum of the e-mail address to solve this problem. We added both properties to the pimo:Ontology (as sub-properties) to be compatible with this important feature of foaf. Additionally we suggest to always use the lowercase version of an e-mail address. If you have two e-mail addresses, prefer the shortest one (in character length) but try to add all. So people can be identified in one of these ways:
The identification of resources (documents, e-mails) is by their URI. The URI used in the RDF triples is the identifier of resources. Other identifications (like identifierRef, etc) are not supported. It can be expected that the problem of identifying files, e-mails, web-resources is already solved by the URI standard. Although we are aware of some deficiencies (for example in identifying local files in a filesystem), we will not suppose a solution here but instead wait until others have solved these problems.
If there is no useful URI scheme for a resource, we suggest that you as developer make up a URI scheme. Many successful software projects have done so (for example, mozilla with their XUL URIs). If you need URIs to identify resources, and have no clue what to do, you can use a sub-space inside the gnowsis URI space, which was made up by us for the gnowsis system. See above for more details and contact the author.
The class pimo:PersonalInformationModel is used to represent instances of a PIMO. For example, Paul's PIMO is also identified inside using an instance of pimo:PersonalInformationModel. This instance is used to link the created things and relations to the PIMO. Every instance of thing, for example paul:Rome, was created inside the PIMO and to note this, a link between the PIMO and the Thing can be made, called pimo:metaDefines.
The instance inside Paul's model is identified using a URI from Paul's namespace: paul:PIMOInstance. Explicitly, we would find these triples:
For each property, thing or class defined by the user, a relation has to be created that states that it was created in the context of the pimo:PersonalInformationModel. Basically, this means that everything entered by the user must be annotated as belonging to the pimo-instance using the pimo:metaDefines property. The pimo:metaDefines relation is mandatory. It is needed to separate different ontologies from each other and to safely mix them. Separation just based on the namespace is not an option.
Luckily, you are not alone. Other people might write very useful classes and relations for the PIMO language you might want to import. Also, the existing RDFS vocabularies like foaf-relationships may be interesting. We call these ontologies "domain ontologies" as they are often called so in literature.
There are two ways to represent and get such a domain ontology:
You see that it is not possible to "just include" RDFS ontologies and hope that it will work. There are stronger constraints on ontologies than in RDFS or OWL, for example each defined Class has to be a direct or indirect sub-class of pimo:Thing and that all properties must have an inverse property. Metadata is needed about the ontology and all elements have to be connected to the ontology using the pimo:metaDefines property.
Let us look at the conversion process to PIMO first and then how you import a PIMO domain ontology. The conversion from RDF(S) is straightforward, you have to:
Your domain ontologies may import other domain ontologies. That is a nice feature of RDF in general, that you can mix ontologies and build larger ontologies in that way. For example, the foaf-relationships domain ontology may require the foaf domain ontology. To state that a domain ontology imports another domain ontology, the relationship pimo:metaImports is used.
Importing a domain ontology into a user's PIMO is then practically done by downloading the domain ontology and storing it into the user's PIMO storage. You should be able to savely mix domain ontologies into the PIMO storage, as each resource in a domain ontology must be tagged by pimo:metaIsDefinedBy. After importing, you then add a relation between the user's instance of PersonalInformationModel and the imported ontology using the pimo:metaImportedDomainOntology to say that you imported it. Attention: if the imported ontology X defines to need another ontology Y by pimo:metaImports, then you must import Y also. All or nothing.
Note that you cannot import one person's PIMO into another person's PIMO, as you cannot look at the thoughts of other people we do not support nor encourage importing PIMOs. They are private to the user and if the user decides to tell something to others, parts may be communicated. We discourage to import the whole PIMO of Paul into the PIMO of Peter.
When domain ontologies are imported, the user might notice that things represented in his ontology are also represented in the domain ontology. For example, the class "Car" might be represented already in your ontology and a domain ontology you download. As the two classes are kept in different ontologies, it might not be suitable to merge them, then it is possible to say that they are just "other conceptualizations" of the same concept. For this we provide mappings that point to these other conceptualizations, namely to map classes, instances and properties.
The interpretation of these statements should be in the sense of owl:sameAs or skos-mapping:exactMatch. A user interface should display the classes mixed together, search engines should also mix the results of two different conceptualizations together. Same with otherRepresentation and otherSlot.
User interfaces should show the user's representation primarily and link to the other representations. The user's point of view is always the right one.
What happens if the user notices that two things are the same? This will happen when algorithms create things automatically and fail during the search for matching things. For example, if a person is extracted from the data of an e-mail and created as an instance of pimo:Person while the person was already an instance there (but labeled using another name).
Merging two things should reuse as much of the data as possible. If two things A and B are merged into thing C:
This leads us to changing the type of a thing and multiple types. Changing the types of a thing may imply that the properties and relations are not valid anymore, if the properties are strongly typed. It is suggested to keep existing properties and relations, even if the ontology is not valid then. If the user changes the type back to the old type, the properties are valid again and also the user may correct the errors manually. The user interface should remind the user of possible errors but should not enforce the correction. Weak typing and ontology-by-examples are the main principles behind this strategy, also that "the user is always right".
Deleting a class entails that instances are typed to the super-class of the deleted class. The topmost class is pimo:Thing. Classes defined in the pimo language cannot be deleted.
Deleting an instance also deletes all relations to and from this instance, including occurrence relations. Note, that also pimo:creationSupportedBy links may be deleted by this, which may result that an algorithm soon creates the instance again (if the user somewhere configured to created instances automatically). See below in section Automatic Creation of Things from ResourceManifestations. In this case, it may be better to use the pimo:metaHidden property to hide it.
Sometimes, things may be outdated or not needed anymore, but they should remain in the PIMO to be searchable. To do this, the user may hide a thing, class or property. Even the default classes like pimo:Person can be hidden, with an exception: pimo:Thing must not be hidden.
The user interface should clearly state that "some things are hidden", to allow the user to find the resources again. Also, search results may choose to rank hidden objects very low or give indications about them. Hiding things may also be initiated automatically, for example by an algorithm that hides things that have not been used for a longer time. To hide something, use this triple:
Note that all system-classes and slots have a property pimo:metaViewLevel. This property indicates if or if not the object in question should be displayed to the user in common data visualizations. The view-level SYSTEM-ONLY means that the object in question should be hidden from the user and only be available in appropriate configuration situations. SYSTEM-USER means that the object may be shown in any visualization. Creating generic visualization algorithms can make use of these values. Note that this property is required and you can always check it in evaluations.
It is obvious that many things that a user can think of are already represented in his resources. Paul already has many entries in his address book, aren't they all candidates for pimo:Thing instances? We know that many algorithms and approaches exist to automatically generate or extend ontologies based on data in text files or other data sources. For the PIMO, one of the requirements from gnowsis states to create active folders, or active things. Automaticly creating thing from ResourceManifestations is needed to make the semantic desktop work. For this, we create a few new relations that connect things to resources and define the existing relations better.
You are already familiar with pimo:occurrence and pimo:occurrenceRef relations. These connect things to resources in which the thing appears. In the context of automatically creating things, the created thing can be connected to the resource via the pimo:metaCreationSupportedBy property. If a PIM concept or instance was generated due to the existence of one ore more resources, here is the link to these elements. Binds an address book card to the person instance or a PDF file to the instance of "contract". It is also important for scanning resources: if a new resource is found, did it already support the creation of a PIMO-thing? The property pimo:metaCreationSupportedBy is intentionally not a sub-property of pimo:occurrence. If the resource is also an occurrence, use both properties to relate the two.
An interesting question remains how a URI and a resource correlate to the thoughts and concepts in the mind of the user. From the user's point of view, it is important to correlate a thought in the mind to a resource in the computer. First there is a thought in the user's mind that leads to the decision to search for a resource in a computer; then the user has to find this resource that his thought is related to. This relation reaches beyond a simple occurrence or a pimo:metaCreationSupportedBy. When the idea represented in the thing is also represented in the resource, they are bound together semantically. The idea that is represented by the pimo:Thing is the same idea represented by the pimo:ResourceManifestation. For this, the property pimo:groundingOccurrence is reserved. This relations should be used in a one-on-one manner: one pimo:Thing is linked to one or zero pimo:ResourceManifestation and one pimo:ResourceManifestation is linked to one or zero pimo:Thing using the pimo:groundingOccurrence. The thought is like an electrical current that originates in the user's mind and searches for a place to discharge, a resource that matches the thought. We defined the grounding resource as follows [Sauermann2003]:
For a thought in the mind of the user there may exist a grounding resource. It is the resource that is associated best to the thought. The symbolic representation of a thought is the grounding resource.
Under discussion: There can only be one grounding resource for a thought?
The term grounding was also mentioned in Georg Dorffner's book "Konnektionismus". Concepts and symbols can be designed in a way that they can be experienced in states of a computer system. He noted that the term was used in the community of artificial intelligence and knowledge theory researchers. [Dorffner1991, page vi]. The reason to speak of a grounding is that the stream of thoughts continues to flow when it has reached the grounding, now the user can follow the links in the PIMO in addition to the associations in the mind. Technically, the pimo:groundingOccurrence is a sub-property of pimo:occurrence, hence a grounding is also an occurrence. The user interface should treat the grounding resource in a special way, perhaps integrating the metadata of the resource or highlighting the link.
The implementation of these features will follow, then we can also provide an RDF-Schema to configure active folders in a general way. The extension of the PIMO to represent these active folders will be part of the upcoming PIMO-api ontology. Look out for it in the next months. Contact the developers of gnowsis at some time.
The semantics of the PIMO language allow us to verify the integrity of the data. In normal RDF/S semantics, verification is not possible. For example, setting the domain of the property knows to the class Person, and then using this property on an instance Rome Business Plan of class Document creates, using RDF/S, the new information that the Document is also a Person. In the PIMO language, domain and range restrictions are used to validate the data. The following rules describe what is validated in the PIMO, a formal description is given in the gnowsis implementation's PIMO rule file.
Following are rules that check if the inference engine correctly created the closure of the model: –
The rules work only, when the language constructs and upper ontology are part of the model that is validated. For example, validating Paul’s PIMO is only possible when the PIMO-Basic and PIMO-Upper is available to the inference engine, otherwise the definition of the basic classes and properties are missing. The validation can be used to restrict updates to the data model in a way that only valid data can be stored into the database. Or, the model can be validated on a regular basis after the changes were made. In the gnowsis prototype, validation was activated during automatic tests of the system, to verify that the software generates valid data in different situations. Ontologies are also validated during import to the ontology store. Before validating a new ontology, it’s import declarations have to be satisfied. The test begins by building a temporal ontology model, where first the ontology under test and then all imported ontologies are added. If an import cannot be satisfied, because the required ontology is not already part of the system, either the missing part could be fetched from the internet using the ontology identifier as URL, or the user can be prompted to import the missing part first. When all imports are satisfied, the new ontology under test is validated and added to the system. A common mistake at this point is to omit the PIMO-Basic and PIMO-Upper import declarations. By using this strict testing of ontologies, conceptual errors show at an early stage. Strict usage of import-declarations makes dependencies between ontologies explicit, whereas current best practice in the RDF/S based semantic web community has many implicit imports that are often not leveraged.
For real-life applications (like the gnowsis beta version) we suggest to separate the storage of resources from the storage of the PIMO ontologies. All automatically extracted information about resources (i.e. from a lokal desktop search engine) should be in one store. All hand-crafted or algorithmically created data from the PIMO should be stored in a capable RDF database.
An analysis of existing ontology languages shows that many problems are solved, but in different ontologies and using different practical ways. The experience from the gnowsis workshops, implementations and many other papers have helped to create a useful ontology for the semantic destop. The suggested PIMO ontology builds a simple and practical ground for future personal information management applications. A practical example and guidelines how to create instances of the PIMO ontology should allow you to implement the PIMO and extend it according to your own ideas. The ontology itself and the according example can be downloaded here: [PIMO-lang, PIMO-example]
With the described PIMO ontology and its practical description, I hope to give a good technical and philosophical ground for the upcoming gnowsis beta implementation.
Some parts are still missing, but will be addressed in upcoming publications on the PIMO.
First of all, thanks to my wife Ingrid Brunner, who allowed me to write this report mostly on my weekends. Just now, she is waiting for me to come home to go for dinner.
In the DFKI Knowledge Management group, we had much input from the EPOS project and its team. Many thanks to Ludger Van Elst who created the PIM-Basic ontology which defines classes and topics and the PIM-Upper ontology which defines detailed classes for people, groups, events, process support, and possible associations to link instances of them. Heiko Maus and Sven Schwarz gave input in many ongoing discussions of the existing ontology languages. Lars Zapf is an expert on Topic Maps. Andreas Dengel, our director repeatedly insisted to keep it simple and usable and is supervising our work. The scenario for the semantic annotation of meetings was thoroughly researched by Man Luo, a diploma student of Leo Sauermann. Also many thanks to Frank Osterfeld and Norberto Fernández for proofreading and error-correction.
Input outside the DFKI and the core gnowsis project came from our friends in Berlin, where we repeatedly committed gnowsis workshops. Leading there, Richard Cyganiak and Anja Jentzsch gave much input regarding what they expect from gnowsis, thanks also to all other participants in the gnowsis workshops. Max Völkel from Karlsruhe also discussed with the authors.
Q: This is so cool, how can I use that for myself?
Thank you. We are currently coding these ideas into an open-source project called gnowsis. It will be part of other software, too, so you might find it somewhere else. If you want to use the PIMO, just download the gnowsis beta 0.9 from www.gnowsis.org in April 2006. Do not download anything before the beta, PIMO is not part of the alpha. If you are a developer, go to http://gnowsis.opendfki.de and see how the status of the project is. If you want to use the PIMO in your own applications, go ahead. The gnowsis project helps you as a java reference implementation.
You can also contact the author. The author is also happy if you cite his other publications.
Q: This is all so technical, where is the big theory behind?
Please read first the recommended literature indicated in the abstract. [RDF-PRIMER], [RDFS], [OWL], [TM-empolis]. The theoretical background is that we use the ideas of Topic Maps and remix them with RDF, SKOS and personal experience from the EPOS project and gnowsis.
This is intentionally technical, because we think that ontologies only work when you have covered different dimensions:
If one of those is missing or failing, the ontology will fail. It is not usable to talk about ontologies only focusing on one level. So the big theory behind is: ontologies only work when describing the meaning behind, the ontology as RDF vocab, example data and code. For PIMO we provide all of them.
Q: Why did you use RDF-Schema as basis and not OWL-Lite nor OWL-DL or SKOS? Or Topic Maps?
Our reasons where all inspired by the principle to keep it simple.
We want to make a good ontology for one application domain: one person expressing ideas for personal information management. Connect the ideas to files, e-mails, webpages and everything else.
Other ontologies were created out of other needs.
Q: You proposed to identify concepts like "Rome" using URIs from wikipedia. This might be a sound solution from the technical side, but first of all these URIs might change and second the URIs at wikipedia identify websites, and not the concepts behind. Isn't this half baked?
True, this solution is far from perfect. Don't suggest us to use the namespace YOU have invented to identify concepts. And don't suggest us to just "change the url of wikipedia a little, so that it is a conceptual uri". We won't just add ".concept" at the end or some other silly thing at the front. People always suggested different solutions for that during the last years and Leo Sauermann gets nervous when you mention these suggestions.
The real problem is: how to identify abstract concepts in software systems, that we use URIs as syntax is a start but the scheme and meaning of the URIs has also to be considered. Others have proposed solutions that also look nice, see [IdentificationIssues]. But from my point of view most of the other solutions either don't scale or are too artificial to be understood and broadly used. What we propose is to use the most popular web-sites can be used to say "this public resource can be used to identify the concept X", because it is popular and people can relate the individual pages on such a website to the concepts behind. For broad adoption of the semantic web, using popular websites can help as normal, non-technical people can relate to them. For movies, people can understand that a website on the Internet Movie Database (IMDB) describes exactly one movie and that this may be used for identification of the movie. Many movie and cinema websites link to IMDB anyway when content authors want their users to know more about a certain movie. Individual persons use the links on their weblogs and inside e-mails, the sentence "Let us watch Life Aquatic tonight" is much easier to understand with the link to IMDB. The same accounts for wikipedia, a website many people can relate to. Also, these popular websites have an intrinsic need to cover most of their user's interest, so we can hope that they are complete enough to cover most concepts we face in daily life. On wikipedia, the user might even add new pages when they miss to identify concepts. We named now two extremely popular services on the web. This is another side of identification - when people interact with mass media and the web, the most popular sources seem to catch an exponential amount of interest. Known as Zipf's Law, this usually means that the top ten items get about half of the world's interest. In the music business, this means that the top ten songs in the charts are sold more than the top 100, inside the top 10 the top 3 are sold more than the others, etc. Once a service has a technical or social advantage above others, it gets boosted by word-of-mouth. The success of google can be seen in this light. From the technical side, the web 2.0 trend for web-services helps, it is often easier to integrate services like wikipedia into custom software than other public ontologies. So you see that the problem is not just of identifying things with URIs but worldwide adaption, social interaction habits of people and statistical indications.
David Booth suggested to either make the distinction between the "four things a uri identifies" either by using different URIs for each context of to use the same URI and a way to express the context. Leo Sauermann has bad feelings about using special URIs to identify concepts, feelings that got stronger during four years of Semantic Web hacking. He therefore chose the "Differentiation by context" approach, that was similarly proposed by Steve Pepper and is also a basis of the Topic Maps standard. So, we give it a try.
Our biggest mistake now would be to proclaim "we build a completely new service to publicly identify concepts, called SEMANTICX and better than anything". This service probably won't beat wikipedia (or whatever is popular at the time) in terms of adoption, scalability and performance and so it won't provide the needed functions. Over time, we expect that different services will get popular, then these other services will be integrated by application developers into semantic applications, we see this as an evolutionary process. If you think our argumentation sounds good, copy it.
Q: How do Topic-Maps model the separation between concepts and resources?
An example would be this Topic Map:
<!-- this is the website I sometimes have to edit -->
<topic id="www.dfki.de">
<!-- to identify the website, I use its web address.
my colleagues will hopefully do the same -->
<subjectIdentity>
<resourceRef xlink:href="http://www.dfki.de/" />
</subjectIdentity>
</topic>
<!-- this is the DFKI company -->
<topic id="DFKI">
<!-- the company is mentioned on the webpage at the specified address -->
<occurrence>
<instanceOf><topicRef xlink:href="#webpage"/>
</instanceOf>
<resourceRef xlink:href="http://www.dfki.de/" />
</occurrence>
</topic>
So we see that the website can be connected to a concept/topic in two ways. Either an occurrence or a subject identity. Separating concepts from documents and linking to resources with two different ways is a needed approach.
Q: I want to tag an email or a webpage, how do I do that?
You find a useful name for the tag, like "SemanticDesktop". Then you connect the e-mail to the thing that is named after this tag. This works like this:
Q: I looked at the way of tagging things, this is so complicated and not as cool as web.2.0. Can't we make it simpler?
You can automate the process completely. If you think it too complicated, shortcut the search for pimo:Things and just always link to the URI matching the tag-name paul:SemanticDesktop. But be warned, this may lead to some quirks later on. Web 2.0? Knowledge isn't simple and you want to have a long-term use of your annotations. At the end, we want to make a Semantic Web and not just web 2.0. If we all tag like del.icio.us, at the end the most important tag will be "important" which is rather dull. Leo Sauermann blogged that he expects, slowly, when people see these problems, the web 2.0 community will embrace ontologies and favor them compared to folksonomies. The representation of tags as things and semantic web resources allows the user to make one tag "part-of" the other, which helps during search. Think of the semantic web as investing to a better future.
Q: Why did you use your own way of importing ontologies, and inverseProperty isn't OWL enough?
No, OWL is not enough. First: we don't use OWL, we use RDFS. We also won't use "just a few relations from OWL" because we think that either use OWL as intended or don't use it at all. Developers will thank us that they aren't tempted to look at OWL and get nervous by this. We have experience in OWL and we like OWL, just not for this special case here. Also read above at our longer answer to RDFS, OWL disallows some things we needed.
Also, OWL doesn't state that the other ontology has to be at the URL given to the ontology. This ignited the rather dull practice of ontology authors not to put their ontologies on the URL indicated by the namespace. Some authors invented funny namespaces for their ontologies, practices we discourage. Tim Berners-Lee also discourages the sloppy behavior regarding namespaces and putting documents there, this is a real stopper for the semantic web.
So: our meaning is different, hence a new property.
Paul's PIMO can be found at:
http://ontologies.opendfki.de/repos/ontologies/pim/pauls-pimo.pprj
http://ontologies.opendfki.de/repos/ontologies/pim/pauls-pimo.rdf
http://ontologies.opendfki.de/repos/ontologies/pim/pauls-pimo.rdfs
| 1 | 2nd Gnowsis
Semantic Desktop Hands-on Workshop, Humboldt Universit� zu Berlin. 10-12
December 2005. On the second gnowsis workshop in Berlin we had a vivid discussion on the future of gnowsis and the semantic desktop in general. Input from the Berlin group again showed that tagging and simplicity may play a key role in the future systems. |
| 2 | iTunes Smart Playlists. Explained online here:
|
| 3 | Wiki-names are longer words without spaces nor funny characters. To seperate parts of the word, uppercasing is used like InThisLongerWord. The idea comes from wikis. |