“Software is not perfect when there is nothing left to add, but rather when there is nothing extraneous left to take away.”
think about it.
via: Gunnar, original source: manifest somewhere on the internet.
personal weblog of Leo Sauermann
“Software is not perfect when there is nothing left to add, but rather when there is nothing extraneous left to take away.”
think about it.
via: Gunnar, original source: manifest somewhere on the internet.
I got victimized by flickr censorship. My photos are still there, but I cannot see the photos by Jake Applebaum anymore. Well, not only I, but anybody from China, Germany and Austria. Lucky me, in Hong Kong you get thrown into jail when you look at art photographs done by Jake.
A post by Xeni Jardin on BoingBoing.net explains how Jake got on the censored photos list:
… I blogged about the case of Oiwan Lam, a well-known blogger in Hong Kong (Links: 1, 2, 3, 4) who’s facing the possibility of a year in jail or a $HK 400,000 fine for having linked to an image deemed offensive by authorities. That image (a non-pornographic, artistic nude) was shot and published by none other than Jake Appelbaum, whose work has been blogged here on BoingBoing many times. …
Oiwan … blames the photo-sharing site’s recently implemented content rating/blocking system in part for the legal situation she now faces in Hong Kong.
Jake believes the program, as implemented, amounts to censorship…
Jake explained the background at said blogpost.
Think global, now the local trouble: I cannot look at the pictures of a person, whom I met personally sometime and who’s work I admire. Here is a pic I took of Jake when we were out eating with other friends in Vienna:

And now, when I click on Jake’s photos, flickr tells me
 .
.
Aeeehhhhmmm. Well, ioerror indeed has photos available for me and I would be interested to see them. So, the social networking website flickr removed the social networking for me. But Gunnar, who sits in office in opposite of me, is not affected by the censorship, because he is Norwegian.
My flickr account will expire tomorrow, and I am so angry about this that I don’t plan continue it. But then you won’t see my sets and pictures anymore and, alas, out of anger nothing good can come.
Any suggestions welcome, I could shutdown my flickr account and move to zooomr (well, maybe not, its a one-man-show) or to smugmug, I could make a new flickr account using a fake id from Norway, etc etc… whats the right thing to do?
To be prepared, I already backed up my whole flickr account, including all comments and tags of the photos in RDF.
Harry Chen blogged about the article Flying machines, desktop software and Web 2.0 by Jay Larock, who compares web and desktop software.
Larock gives three reasons why we will continue using desktop computers and desktop software (abbreviated by me):
I copy all of these arguments, and add a fourth: some people don’t trust free services on the web, who may censor your work, suddenly go out of business, or be hacked, and therefore some people keep a copy of their data on their own harddisks and enjoy desktop apps.
Harry then comes to this conclusion:
We shouldn’t ask the question whether desktop software will survive in the age of Web 2.0 (yes, they will survive). But instead, we should ask: how can Web 2.0 applications (and Semantic Web applications) complement the existing functions of desktop software, so that the users can be made more productive?
This question was asked differently by me in 2003 and answered in this thesis:
http://www.dfki.uni-kl.de/~sauermann/papers/sauermann2003.pdf
“If the goal is to have a global Semantic Web,
one building block is a Semantic Desktop,
a Web for a single user. “
After this, Stefan Decker and Martin Frank published their “Networked Semantic Desktop” paper, and you find several implementations that bring Semantic Web technology to the desktop, www.dbin.org, www.openiris.org, gnowsis.opendfki.de.
And lots more that are under the “radar”. So, the questions is good, but using the keyword “Semantic Desktop” you easily find an answer. There are many articles about it. If you have more questions, ask the people@semanticdesktop.org.
So yes, its indeed a good idea to combine web 2.0, semantic web and desktop computing 🙂
Dan Connolly blogged about units in RDF.
We have the same problem in Nepomuk, but for more practical things like measuring the size of a file (MB, KB, B, b) or the length of a song (1h, 3m 20s, 200s). Actually, we are searching for a solution that will work in normal KDE and doesnt require a PhD to understand, the typical KDE developer will take 10 minutes reading the FAQ and then start using it (note: 10 minutes for RDF, Turtle and the Unit ontology 😉
Will blog again once I have checked what our status is.
Danish Nadeem has finished his master thesis on “Cognitive Aspects of Semantic Desktop to Support PIM”.
Here is his publishing post in full length:
The proper and immediate object of science, is the acquirement, or communication, of truth […]
Inspired by the quote here i intend to publish my Masters thesis. The title of my Masters’ Thesis is: “Cognitive Aspects of Semantic Desktop to Support Personal Information Management“. It is submitted now at the Institute of Cognitive Science.
Many thanks to Leo Sauermann for his close supervision, constant support and valuable inputs to realize the work.
The abstract :
This thesis examines issues on Philosophy of Artificial Intelligence (AI), Cognitive Science and Mental Models. The research provides a philosophical grounding for the researchers in Personal Information Management (PIM). An overview is given on various philosophical aspects of computer-based activities. Discussions on the theories relevant to understand the goals for the Semantic Desktop community are elicited. The ideas discussed in the thesis are intended to emphasize a theoretical foundation, with respect to the Semantic Desktop long term goals. The goal of this thesis is to examine the theories of Philosophy and to provide a conceptual idea to design user-intuitive Semantic Desktop applications. The challenges of the Semantic Desktop evaluation are highlighted and suggestions are made based on Gnowsis evaluation. The work tries to induce scientific curiosity among the Semantic Desktop researchers.
Download as [ pdf] size ~1 MB
Thanks to the CPAN Perl community, you can get all your Flickr pics as RDF-if you have linux, its just a few steps away.
The relevant documentation:
Perl documentation is excellent. I have seldomly seen such a clean
documentation as Aarons tool and the other tools used. It is minimal, it is simple, it doesn’t miss one point.
He has example RDF output and example documentation, how to tie everything together was easy to find out using CPAN.org.
You will need a flickr API key and secret.
At this point, you need also the auth_token of the key, this is trickier to do.
I moved sidewards to get the token, as I coded with flickr before,
I had a PHP application running that I used to get the auth_token.
The php-flickr API was Dan Coulter’s phpFlickr Class 2.1.0,
and it has this getToken.php file that you can tweak to do the right thing.
I am sure you can get the same with Perl. Once you got the key, secret, and auth_token, install the libs:
get Perl (well, a typical linux distro depends heavily on Perl, so you probably have it already).
get the CPAN module for Net::Flickr::Backup, I used the perl cpan shell for this (sudo is needed because it installs the perl modules in the shared libs):
in the perl shell, install the backup module:
Now, it asks you many questions. In my case, pressing return most of the time did a good job.
Once you have it installed (perl will say if it doesn’t), you can run the Backup by writing a script.
I created two files, one for the config, one for the perl that runs:
flickrbackup.config: (note: the aaaaaa are used to hide my secret keys)
#[search]
#tags=cameraphone
#per_page=500
[backup]
photos_root=/home/media/photos/flickrbackup
scrub_backups=1
fetch_medium=0
fetch_square=0
force=0
[rdf]
do_dump=1
#rdfdump_root=/home/asc/photos
runbackup.pl:
my $cfg = new Config::Simple(filename=>”flickrbackup.config”);
my $flickr = Net::Flickr::Backup->new($cfg);
my $feedback = Log::Dispatch::Screen->new(‘name’ => ‘info’,
‘min_level’ => ‘info’);
$flickr->log()->add($feedback);
$flickr->backup();
Now run the scripts:
Lean back and watch the photos + RDF manifest in your filesystem magically. In this case, RDF as a file format is helpful becaue it allowed Aaron to mix different aspects of the metadata.
You may get an error because some XML library misses, my error message contained
“Can’t locate XML/LibXML.pm in @INC”
Luckily, this mailinglist post tells you what to do:
This may fail with some weird message, I ignored this and run my backup script again.
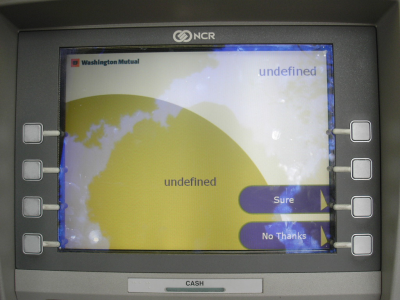
a nice question, asked to ATM users:
Undefined?
see the image at the dailty WTF (not including it here, its their pic)
via: litfass, DFKI internal KM system.
🙂

so it seems: 23:00, MQ vienna.
Tonight, some guys from the Vienna Metalab, in cooperation with Idontknowwhoelse, are going to do amazing urban hacking in vienna.
Once and for all: be there. At this moment they get their fuckin Laserguided Graffity System shit together, which is a hack/adaption of stuff done by the Graffitti research lab.
Also, it seems that 1000 throwies will find new plazes to stick and glow.
fuckit, and I am stuck in Kaiserslautern.
I met a journalist from xml-magazin.de at the webinale 2007, and he interviewed me recently. Interview is in German!

http://xml-magazin.de/itr/news/psecom,id,36225,nodeid,68.html
I answer questions about Semantic Desktop, Semantic Web, and RDF, and often the question is “why is RDF not used?”, well, …
der gute alte IRARK Film vom Grenz und mir, den er jetzt auf Youtube gestellt hat, kudos an Niko.
immer noch gültig “sie haben den verdammeten Krieg angefangen nun müssen sie ihn auch zu ende bringen”. “Es ist nur eine Frage der Zeit …”
Es ist verrückt, wir hatten in den ersten Tagen des Kriegs im Jahr 2003 gedacht das wird nichts mit Blitzkrieg, und leider ists wirklich daneben gegangen.
{kind=link}